|
RSS, OPML and the XML platform.
|
|
RSS, OPML and the XML platform.
|
 R|mail.
R|mail.
R|mail.
R|mail.Apple appears to be developing a Web-based RSS reader for the iPhone.
Around the blogosphere...
R|mail.Jash Catone asks if the Facebook platform is a fad or a success. It turns out that two Facebook applications have been sold for small profits. I suspect that it's both a fad and success. Facebook got developers to write apps for them and lock-in users. Developers made coin. Users got apps. That's a lot of success. Will people be writting Facebook apps in 3 years? I doubt it. That's a fad.
http://www.readwriteweb.com/archives/facebook_acquisitions.php
R|mail.I've had this one in the pipes for awhile ;-) David Rothman discovered that you can use Yahoo! Pipes to translate your feeds to many languages.
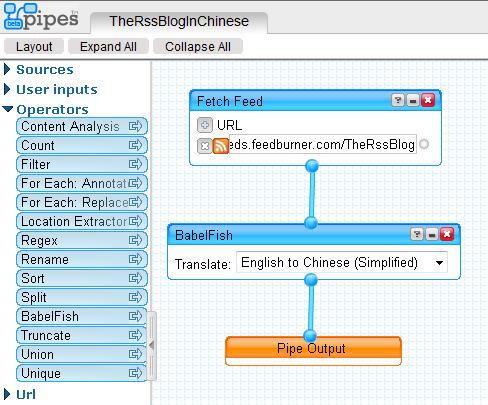
Much is lost in the translation, but here's The RSS Blog in all your favorite languages.
This is my first Yahoo! Pipes non-trivial experiment. Dave Rothman has more details, so please read his blog.
http://davidrothman.net/2007/02/11/using-pipes-feed-translation-and-topping-technorati/
R|mail.
R|mail.
R|mail.
R|mail.
R|mail.The RSS Best Practices Profile has been revised and is close to being submitted to a vote of the RSS Advisory Board. Aggregator developers and RSS publishers who'd like to submit recommendations for inclusion in the document are encouraged to...
R|mail.
R|mail.
R|mail.I got a report from a user today that Craigslist is also publishing invalid RSS. In this case, they are missing the colon in the timezone offset.
<dc:date>2007-06-17T10:29:18-0700</dc:date>
There's definitely an up-tic in the amount of invalid RSS being produced.
Rogers Cadenhead points out that RSS 2.0 is gaining market share since the RSS Advisory Board expanded. In the same period, Atom as lost market share.
Tim Bray points out that there's a new version of RSS (RSS 2.0.9). He also mentions that Atom has been stable since 2005. He fails to mention that Atom feeds produced before 2005 are incompatible with the current draft of Atom and that the current version of RSS is backwards compatible to RSS 0.91 (written in 1999).
I think these two points are well connected. All Atom feeds were broken in 2005 by a major change to the format. RSS, on the other hand, has remained backwards compatible thru the ages. Thanks mostly to the stubbornness of Dave Winer. Ya, we know he is stubborn, was and remains, but it turns out he was also right.
https://workbench.cadenhead.org//news/3227/tim-bray-rss-twice-good-atom
R|mail.Of late, I've noticed an up-tic in the amount of invalid RSS being pumped into the Web. In many cases, the invalid RSS is being produced by software engineers that should know better. It's not hard to add a simple SOAP call to your regression tests. Or simply visit the W3C Feed Validator Service during your testing cycle.
Who's the culprit of this blog entry. How about reddit and simpy? The simpy feed is simply horrible.
R|mail.
R|mail.
R|mail.This blog entry discusses how best you can test your RSS software for proper encoding/decoding and report the results to me. I'm separating this document into two parts; publishers and readers. The section on publishers will target blogging systems; Wordpress, Blogger, etc. The section on readers will target RSS readers; My Yahoo!, iGoogle, etc.
Testing an RSS publishing system involves the following steps.
Testing an RSS reader involves the following steps.
All entries will be entered into a draw ($20 at Amazon). The person who submits the most entries also wins ($30 at Amazon). Points are awarded as follows; 1 for entries with no bugs, 2 for entries with bugs, 1 for corrections and bonus points for amount of detail.
The most confusing part of RSS is understanding how to encode textual elements other than the item/description. You see, item/description is special. It's encoded as HTML, which means you double escape certain characters. The problem is all the other textual elements which by definition should not be HTML encoded, but rather they should be plain text. Encoding plain text doesn't sound like much of a problem, but when it comes to RSS, everything is really simple, but encoding plain text is really difficult. Why? Because many RSS publishers have encoded these other elements as HTML. This, in turn, resulted in many RSS parsers double-decoding these elements.
The entire problem can be described with a few simple examples of how you might encode and decode an ampersand symbol.
| Text to Encode | Single Encoded | Double Encoded |
| This & That | This & That | This &amp; That |
| This & That | This &amp; That | This &amp;amp; That |
Encoding is the easy part. There are only really two cases to consider when encoding. In decoding, we have to address all three cases produced by the encodings.
| Text to Decode | Single Decoded | Double Decoded |
| This & That | This & That | error |
| This &amp; That | This & That | This & That |
| This &amp;amp; That | This &amp; That | This & That |
There are actually more than 2 ways to encode. Beyond single and double encode, you can also use entity and decimal and hexdecimal numeric encoding.
| Text | Entity Encoding | Decimal Numeric Encoding | Hexdecimal Numeric Encoding |
| This & That | This & That | This & That | This & That |
Using combinations of each, you can actually encode the same string 12 different ways. The current dispute (problem) has nothing to do with entity or numeric encoding, so I'll use entity encoding for the remainder of this document and I'll never mention numeric encodings again, to save you a bit of confusion.
As I described above, the item/description element is double encoded and everything else is single encode. Following are example RSS feeds with properly encoding for title and description elements.
| Test Case | Text to Encode | RSS |
| Test Case #1 | This & That |
<rss version="2.0"> |
| Test Case #2 | This & That |
<rss version="2.0"> |
You can download copies of thisandthat.1.xml and thisandthat.2.xml. You can also subscribe to them using your RSS reader and tell me the results. I tested them in IE7 and both worked as per the RSS spec.
This is all nice, but we don't live a perfect world and as noted, some developers are double encoding their titles. Here's some example of feeds that a not properly encoded.
| Test Case | Text to Encode | RSS |
| Test Case #3 | This & That |
<rss version="2.0"> <title>This &amp; That</title> |
| Test Case #4 | This & That |
<rss version="2.0"> |
You can download copies of thisandthat.3.xml and thisandthat.4.xml. You can also subscribe to them using your RSS reader and tell me the results. I tested them in IE7 and both fail as expected.
Some have decided that since some people are doing the right-thing and some people are doing the wrong-thing, that they could try to predict which and present the end-user with a best guess. The strategy here is to double decode every textual element and if that results in an error condition, then single decode it. This strategy will actually compensate for some feeds that improperly encode. In fact, both test case #3 and #4 will actually work using this compromise. The problem? Test #2 will actually fail using this compromise.
In the next few days, I want to make a push to correct vendor bugs in this area. Their are two tests. I'm going to ask my readers to publish two blog entries (case #1 and #2 above), point to the entries and tell me what the RSS items fragment looks like. I'm also going to ask my readers to subscribe to case #1 and #2 above and tell me which RSS reader you use and how they look in your reader. For every test case that succeed, the reader earns 1 point. For every test case that fails, the reader earns 2 points. Don't worry about duplicate entries, they count, as long as you actually did the work. Whomever gets the most points wins ($30 of whatever they want from Amazon). I'm also gonna do a random draw of all the participants for another prize ($20 of whatever they want from Amazon).
Once the results start coming, I'll publish them and file bug reports with the vendors. The goal, for me, is to improve the encoding for RSS.
I may have typos or mistakes above. If you point them out, I'll award you another bonus point.
Update: As James and Chip noted in comments, the links to test case #3 and #4 were wrong. James points out that I missed CDATA encoding in my enumeration of encoding methods (that was a glaring oops). Two points for James and 1 to Chip for typo corrections.
R|mail.This is a test of the this & that protocol.
Conclusion: I was testing my own software to see if I properly encoded the ampersand character in the title and description. I'm gonna run a contest, where users report which publishers and aggregators are respecting the encoding. I'm thinking that whomever provides the most correct data points wins ($30 at Amazon) and then have a draw with all remaining participants for a second prize ($20 at Amazon). I'm starting by offering the $50 in Amazon merchandise. If anybody else wants to sponsor with additional prizes, then please ping me. Don't submit entries yet. I'll announce the contest ASAP and you can submit entries then.
R|mail.
R|mail.The voting history of the RSS Advisory Board members. The only requirement of membership on the board is to vote. Last time I published this spreadsheet, somebody resigned from the board. Compiled by hand. Sorry for any errors.
|
v = voted, x = wasn't a member at the time
The proposal to revise the RSS specification has passed 5-1 with RSS Advisory Board members Matthew Bookspan, Rogers Cadenhead, Christopher Finke, Randy Charles Morin and Paul Querna voting in favor, Eric Lunt voting against and members James...
R|mail.Simone Carletti has once again produced an amazing RSS-related tool. Apache Log Analyzer 2 Feed will produce an RSS feed based on events in your Apache log. You could subscribe via RSS to be notified when GoogleBot visits your website, when a user surfs your site and much more.
R|mail.Today, the topic of language surfaced on the rss-public mailing list. Rogers noted that the <language> element was used in 51% of the feeds he checked. Nothing interesting there. He also noted the <dc:language> element was used in 36% of the feeds. That was really weird. Rogers wondered if it was worth covering <dc:language> in the RSS profile. With so many people using <dc:language>, it surely does belong in the RSS profile, but I would be inclined to advise publishers that the element is redundant and should be avoided where <language> is sufficient. Ralph Giles added that <dc:language> can appear as a child of both the <item> and <channel> elements, whereas <language> can only appears as a child of <channel>. That's a great use case of <dc:language>. There's also a third perfectly valid and rarely implemented way of denoting language in RSS; the xml:lang attribute.
There's some confusion as to what are the acceptable values of <language>. The primary source is the list of language codes in the spec's appendix. But any language code that can appear in HTML, can also appear in RSS. This includes both ISO639 language codes and ISO3166 language codes.
As part of the research for the RSS Profile, I compiled statistics on how frequently RSS core elements and namespace elements appear in feeds.The full report reveals that the most popular namespace element is dc:language from the Dublin Core...
R|mail.In RSS Profile research, I analyzed how frequently RSS core elements and namespace elements appear in feeds.Here's the compiled stats for item elements. Part one covered channel element usage.The full report reveals that the most popular...
R|mail.The newest draft of the RSS Profile includes tests conducted by James Holderness to determine how well the TTL element is supported in RSS.
R|mail.You can vote for your favorite Web applications in the Webware 100. 250 web apps were nominated in 10 categories, only 100 will survive. My picks follow.
Do you think I like Google?
R|mail.
R|mail.James Holderness compiled a great article on the use of TTL by RSS clients. His main point was "We [cut] do not know of any [RSS clients] that treat [TTL] as a minimum refresh frequency."
The RSS Blog is published by Workbench
