|
RSS, OPML and the XML platform.
|
|
RSS, OPML and the XML platform.
|
 R|mail.
R|mail.Google did something disruptive, yet again. They just released a new browser plug-in called Google Gears that allows Web browser-based applications to work offline. It works with Internet Explorer and Firefox on Windows, Mac and Linux. There's also a developer API that allows anybody to create offline Web applications in Javascript.
Around the blogosphere...
Update: I figured out how to view Scoble's video online (and embed it).
Google's blog search seems to have been drained of content. I don't remember how many links I had yesterday, but The RSS Blog currently has only two inbound links. Back to Technorati? Maybe not. I need a new blog search engine. One that works.
Update: I'm now down to zero links and many of my others sites have also experienced similar. Google blog search is severally broken.
Let me easily predict the future. The next big thing is livecasting. This is similar to podcasting, except that you can do your show live, like The Chris Pirillo Show. These are both audio only or full video. Listeners of the live show can chat with each other and the host. The show can then be embedded on a blog to create an archive. You can consider this the next evolution of podcasting and YouTube. People want their 15 minutes of fame and now it's really easy to get it. In fact, when livecasting catches on, we can all have our 15 minutes of fame, once a week or even once a day.
Jason Schramm is the only livecaster that I know, but there are hundreds, maybe thousands already doing this. Jason does the AppleWatch livecast. I haven't listened to him live. He was on earlier today and sent me a link, but I was napping and didn't get the link in time to listen to his show. I would've liked to. Most livecasts are basically teen chats. A place for guys to hit on girls and girls to socialize.
There are a couple of such websites that really look interesting to me and are almost there, but not quite. If you know of others, then drop me a link so that I can review them too.
BlogTV is a live videocasting site. I went to the Canadian release party earlier this year. It was pretty evident that this was compelling technology, but the implementation was horrible. The HTML was invalid, the embed autoplayed. It only worked in Canada, so your audience was limited. I tried it again today and it looks like they've fixed a lot of things, but problems remains. The first big problem with BlogTV is that it geolocates users and stuffs them in a sandbox. In other words, Canadians can't watch U.S. shows and vice versus. The second big problem is that the chat client doesn't work. When I launch a live show, I get a bunch of security error message and the chat client fails to load. I suspect they didn't test in Windows Vista's user mode.
TalkShoe is a live audiocasting site. Jason Schamm uses TalkShoe. I reviewed them earlier this year and it was simply too hard. Dave Nelson of talkshoe told me they are working to make it easier. They currently have one major problem. To host a show, you either have to call-in by phone or Skype. It would be best if they had an integrated voice into their client download. The best part of TalkShoe is that they will pay you $50 when you record your 10th show. It's almost worth doing it for the $50 via PayPal. They even have a referral program. If you want to check out TalkShoe, then send me your first name, last name and email address and I can refer you. That'll give me an extra 25% on your earnings.
Today is one of the biggest Web 2.0 buyout days, with MySpace owner News Corp buying Photobucket for $300M and eBay buying Stumble Upon for $75M and CBS buying last.fm for $280M.
Around the blogosphere...
R|mail.A new draft of the RSS Profile adds the result of tests conducted with RSS support in the Apple Safari browser. The profile relies primarily on tests using Bloglines, BottomFeeder, FeedDemon, Microsoft Internet Explorer 7, Mozilla Firefox 2.0,...
R|mail.One of the most misunderstood element in RSS is the <ttl>. It stands for Time To Live and it controls how often a feed should be refreshed. In this blog entry, I'll try to describe as much as possible about the element, so that others can make their own decisions on how to use it.
The specification has two sections that describe TTL. Under <channel > elements it says.
ttl stands for time to live. It's a number of minutes that indicates how long a channel can be cached before refreshing from the source.
A separate section on TTL says.
ttl stands for time to live. It's a number of minutes that indicates how long a channel can be cached before refreshing from the source. This makes it possible for RSS sources to be managed by a file-sharing network such as Gnutella.
Although Dave Winer's words are not gospel, they do help. Dave was the primary author of the RSS 2.0 specification. Dave said the following about TTL.
Suppose you have a copy of Gnutella running on your machine, and I have one running on my machine. My machine wants a copy of a certain feed, so it asks your machine if it has it. Your copy of Gnutella looks in its cache, finds a copy of the feed, takes the lastBuildDate, adds its ttl value. If the resulting time is greater than the current time, it says yes, I can give you that, otherwise it says no. If your Gnutella strikes out, if everyone it asks says no, it reads the feed from the feed's server.
What Dave seemed to have envisioned is that their would be RSS caches. These caches would be polling RSS feeds periodically and serving them more often. These caches would reduce the overall bandwidth demand on a popular feed.
The most popular feed cache on the Internet is Google's FeedFetcher. FeedFetcher fetches feeds periodically and serves them to several different subsystems and websites run by Google. The RSS Blog has 1381 Google subscribers. Some of them use Google Reader, others use iGoogle. Imagine if Google fetched The RSS Blog every time a user wanted to see my blog in iGoogle or Google Reader. That would create a lot of web traffic. Instead, Google has one cache that polls my feed several times per day and serves the cached copy to all the subscribers and applications.
Now, we have all these caches out their polling feeds, but how do we tell them how often to poll for feeds. If I run a news service whose RSS feeds get recycled every 10 minutes, then I want feed caches to poll my RSS feed at least every 10 minutes, maybe even every 5 minutes. On the other hand, if my feed is updated exactly once per month and dissemination of the feed is not urgent, then there's no reason for these caches to be re-fetching my feed every hour. Another use case is an Amber Alert RSS feed. This is urgent information that isn't updated very often, so I don't want people looking at a feed that is 50 minutes old. Ambert Alerts must get disseminated quickly. In this case, I might set the TTL to 5 minutes.
The draft RSS profile has more to say about TTL than everybody else combined. Here's a cut job from the profile.
Requirements
The channel's ttl element represents the feed's time to live: the maximum number of minutes to cache the data before an aggregator requests it again (optional).
Recommendations
By convention, most aggregators check an RSS feed for updates once an hour. The ttl, skipDays and skipHours elements provide a means for publishers to offer guidance regarding a feed's frequency of updates.
Support for ttl appears sparse among aggregators, in part due to disagreement over its meaning in the RSS specification.
Some aggregators use the TTL value as the minimum frequency of update checks on a feed. A test feed with a 90-minute TTL was checked more frequently than that by BlogBridge, Bloglines, FeedDemon, Google Reader, GreatNews, JetBrains Omea, My Yahoo, NewsGator Online and RSSBandit, which either indicates that TTL is used as a minimum or is ignored by the aggregator.
Other aggregators use TTL as the maximum frequency of update checks. Three aggregators won't check a feed more frequently than its TTL: BottomFeeder, Internet Explorer 7 and Opera 9.
Aggregators may check a feed for updates more frequently than its TTL. When an aggregator's cached data for a feed is older than the feed's TTL, the aggregator should request the feed again rather than rely on cached data.
This definition seems a bit too aggressive for me, but I'm generally ok with it too, but as a secondary source. Let's assume a feed cache has a very unpopular feed that is pulled at most once per month. There's no sense fetching that feed every hour, just because the TTL says so. Rather, when the feed is requested, the cache should examine when the feed was last pulled, add TTL minutes and determine if it should refresh from source before responding to the request, or respond with the cached copy.
In practice, I've seen several uses of the TTL. Many aggregators let the user determine how often a feed is polled and some of those will use the TTL as a default (or 60 minutes if not present). Some aggregators simply use the TTL as a hint to determine how often they are polled. The RSS draft profile is likely a good source for examples of these behaviors. Most aggregators simply ignore TTL and do nothing with it.
Make you own. TTL is rarely supported by both publishers and clients.
Scott Kingery write a great 7 tip blog entry on getting more blog readers by properly using RSS.
http://www.techlifeweb.com/2007/05/29/how-come-i-have-no-readers-part-1-feeds/
R|mail.Today, I responded to Dave Winer's request for a counter-proposal. We've been in disagreement since the RSS board began using its right to clarify the specification in January 2006. The debate got hot when we tried to add four additional words to the spec last week. The proposal follows.
Here's a starting point that would be acceptable to me and I could present to the RSS advisory board.
Dave concessions
- concedes that we are the true RSS advisory board
- links added to Harvard site to refer to the current board
- support for the RSS profile (even though he disagrees with some of
it)- update Harvard spec to point to the rss-public mailing list instead
of the dead forum
RSS Board concessions
- concedes previous modifications to the spec
- drop our version of the RSS spec
- redirect our old spec webpage to the Harvard spec
- link to the Harvard version of the RSS spec from the sidebar
Last week, I was working on a bug report related to an OPML import. I quickly realized that the OPML was invalid and I fixed the OPML for the user. The user filed a bug report with the RSS agent that produced the OPML file. The developer responded that he thought the validator was wrong, he also suggested the issue isn't documented anywhere and that the importing agent was at fault. I replied with a link to the OPML spec and an excerpt that addresses the issue. We still have work to do on OPML interop. This has to begin with the OPML validator. Let's make this OPML validation day. Please export your OPML, validator it and note issues in the comments. Problems will be forwarded to the developer of the OPML tool.
This last week, the rss-public message board exploded in controversy. The biggest of which is my assertion that sorting items by reverse chronological order is an RSS convention and that attribute extensions should specifically be allowed in RSS. The biggest dissentor is Dave Winer who has refused to be specific about exactly what he think I said is absolutely not true, even thought I've asked him twice.
More than 3 years ago, Dave Winer asked me what I'd do if I were on the RSS advisory board. Dave then repeatedly said that the role of the RSS Advisory Board is to answer questions about RSS. Go thru any of the various RSS mailing lists and tell me who has consistantly answered user questions. That would be me and only me. And yet Dave attacks me.
Honestly, I thank Dave for giving us blogs and RSS, but when someone attacks you for trying to help users, then he is nothing less than an asshole unnice guy. Especially when he won't admit why he attacked you.
Thursday, Dave Winer told us that the RSS Advisory Board didn't exist. Today, he wants to join.
Alex Bailey dropped me a note to tell me about his .NET RSS reader, QuickRSS. You can download it here. He's looking for reviews. If you blog one, then pop me an email and I'll add it to my daily links.
R|mail. Mark Woodman wrote today about The Plumbing Fable. It's a tale about the Really Simple Sink. After reading his fable, I remembered this place. At first I couldn't place it, but now I remember the dream I had. Somehow, Mark and I have had very similar
Mark Woodman wrote today about The Plumbing Fable. It's a tale about the Really Simple Sink. After reading his fable, I remembered this place. At first I couldn't place it, but now I remember the dream I had. Somehow, Mark and I have had very similar dreams nightmares. This is what I recall of that scary night, tucked deep under the covers, all alone, in the dark basement of my house.
I walk into a store. It was called Sinkdication, a plumbing store that specialized in sinks. They had the top sink salesman in fableland. His name was Dave. The store wouldn't have existed without Dave. Dave had expanded on an old employees designs and added his own touches to create the ultimate sink; called the Really Simple Sink. The sink was a hit and everybody had to have a Really Simple Sink. Everybody was happy and Sinkdication was the fastest grown plumbing store in all of fableland. Sinkilizer, the mayor of fableland, declared "Life is grand! Sinks for all!"
Eventually other salesmen at Sinkdication started to come up with enhancements to the Really Simple Sink, but Dave wouldn't let them package the enhancements with the Really Simple Sink. They had to sell the enhancements as separately priced add-ons. Eventually, many of the engineers got fed up with dogmatic Dave. They vowed to create their own sink. They called their sink the Pie Sink. After several iteractions, they renamed it Echo Sink. After several more iteractions, they renamed it Nota Sink. After several more iteractions, they renamed it Formerly Echo Sink. And finally the name Atom Manufacturing Sink stuck.
The Atom Manufacturing Group discussed their designs each day after work for their ultimate sink. The design changed and changed and changed and change. The one feature that remained the same thru the design process was the arm REST. Brink, the head of the Atom Group, declared that Atom will have SOAP. They released pre-manufacturing specs for their ultimate sink to grandiose acclamations. The biggest house developer in town, Booble, decided to only make houses with plumbing rough-ins that fit the Atom Sink. They built millions of houses to spec.
Unfortunately, manufacturing the Atom Sink took 18 months and Booble needed millions of sinks. So other plumbing stores in town released their own Atom Sinks based on the pre-manufacturing specs to service this supply shortfall. During production-line setup, better ideas arose and when released 18 months later, the Atom Sink had a new and better adapter. They released new manufacturing specs based on this much better design. But, Booble and the other house developers continued to create new houses based on the pre-manufacturing specs. Residents of the town went to the Sinkdication store and asked for Atom Sinks for their houses. The Atom Group always replied, "Your sink is obsolete. Refit your house to our new specs." Eventually, the Atom Group went back and added one additional sentence to the pre-manufacturing specs.
DO NOT implement it or ship products conforming to it.
 Booble had placed an order for 1 million Atom Sinks and had to retrofit all the recently built houses in town. Developers all around town began retrofiting their houses and sinks to support this new manufacturing spec. Some residents of town didn`t know about the change in sink. They tried to install the Atom Sink in the pre-spec hookups. When they tried to return the Atom Sinks, they were told, "Their sink rough-ins were obsolete." Johnsink, a fan of the Atom Sink yelled "Didn`t you read the specs? DO NOT implement it or ship products conforming to it." Eventually, Booble got fed up with confusion and installed both Atom and Really Simple Sink hookups. Every house developer and every sink manufacturer in town were now producing sinks that conformed to all the specifications. Nick Demon, a sink manufacturer cried, "Just use one sink hookup." Residents refused to buy houses that didn't support both Atom and Really Simple Sink. Costs went thru the roof.
Booble had placed an order for 1 million Atom Sinks and had to retrofit all the recently built houses in town. Developers all around town began retrofiting their houses and sinks to support this new manufacturing spec. Some residents of town didn`t know about the change in sink. They tried to install the Atom Sink in the pre-spec hookups. When they tried to return the Atom Sinks, they were told, "Their sink rough-ins were obsolete." Johnsink, a fan of the Atom Sink yelled "Didn`t you read the specs? DO NOT implement it or ship products conforming to it." Eventually, Booble got fed up with confusion and installed both Atom and Really Simple Sink hookups. Every house developer and every sink manufacturer in town were now producing sinks that conformed to all the specifications. Nick Demon, a sink manufacturer cried, "Just use one sink hookup." Residents refused to buy houses that didn't support both Atom and Really Simple Sink. Costs went thru the roof.
On my way out of town, I overheard two residents talking. The first resident, named Reinsinker, had heard that Dave sold his Really Simple Sink manufacturing plant to SinkBench for $1 million and was now working on a Really Simple Fridge. The other, named Sinkry, heard that SinkBurner, a competing sink manufacturer sold their plant to Booble for $100 million and Spystolo Sunk, the founder, made a mint.
"Ya SinkBurner," said Reinsinker, "It had hookups for Atom Sink cold water, but not hot. But they had great Really Simple Sink hookups too, so I only had to retrofit my house to get hot water. Cost me a bundle, but it could've been worse."
"That's the nice thing about owning a 10 year old house," said Sinkry. "I've had the Really Simple Sinks for 10 years and every once in awhile Dave had a sale and I picked one up. They were so simple to install, I didn't even have to call the plumber. In fact, every Really Simple Sink came with the same 10 yr-old instructions. But I heard some Moron wants to update them."
At which point, I left town fearing my life.
Note: Kudos to the first person that matches up all the proper names to their blogs. Sorry for the typo. I wrote this while cooking supper (how many Ps?). If you find a typo, then please ridicule me in the comments.
The latest draft of the RSS best-practices profile includes advice on the Slash namespace, extensions to RSS that support features of the content-management system that powers Slashdot. Feedback is encouraged on RSS-Public.
R|mail.A funny story by Mark Woodman about three sink salesmen named Dave, R.C. and Sam. I think I was at this store.
R|mail.Today, Dave Winer says the RSS Advisory Board doesn't exist. Dave created the RSS Advisory Board. He later resigned from it. When I was appointed to it, he tried to get me to resign. Now he claims it no longer exists. Why? Because Dave said so? Dave, if you wanted to maintain control of the board, then why did you resign? When you resigned, you forfeited the right to decide its future. Just because you may disagree with what we are doing, doesn't restore you any rights.
I assume you are upset that we are making small clarifications to the RSS specification. And if Harvard doesn't want to respect that, then so be it. But when the RSS Advisory Board was created, the mandate was clear and included the right to make clarifications.
What does the advisory board actually do?
We answer questions, write tech notes, advocate for RSS, make minor changes to the spec per the roadmap, help people use the technology, send flowers to developers, maintain a directory of compatible applications, accept contributions from community members, and otherwise do what we can to help people and organizations be successful with RSS.
http://www.scripting.com/stories/2007/05/24/advisoryBoardFinale.html
Rogers Cadenhead also wrote a response to Dave. He points out that Dave clearly gave permission to the remaining board to make spec clarifications.
https://workbench.cadenhead.org//news/3217/dave-winer-and-rss-advisory-board
A happening today made me realize I had a great followup for the unblogosphere conversation. In my original post, I talked about how many b-list and c-list bloggers link in every post to a-listers, just hoping to get that one link back, which often never happens. Today's happening proves that not linking to an a-lister is just as good a strategy. I have always refused to link to Mike Arrington because I think he's a fraud. When his blog broke the FeedBurner-Google confirmation, I sought out another blog to link to, because I refuse to link to him. In that attempt, I accidentally linked to someone that plagiarized the original author. After watching many of my friends link to this a-lister over-and-over for years with no return link, I was able to get one, by simply not linking to the same a-lister. I think this is validation, that expanding your linking behavior to b-listers and c-listers works, even if by accident.
R|mail.Google bought FeedBurner for $100M. Here's a big congratulations to the first really big RSS success story. Congrats to Dick Costolo, Eric Lunt, Steve Olechowski, Matt Shobe, Rick Klau, Don Loeb and the rest of my friends at FeedBurner. And thanks for bringing RSS to the masses. Who could'a predicted this?
Update: Shelley Powers is the first to say bye to her FeedBurner feed because she's paranoid that Google knows more about her blog readers than she does. She used FeedBurner's exit strategy. Can you believe that? FeedBurner provided an exit for their users. Those guys were are classy.
Lost in the FeedBurner news is that this wasn't their first success. Back in the bubble, the same four founders sold SpyOnIt to 724 Solutions for $53M. In a private chat, a friend noted that whatever Dick and team do next, we're jumping that bandwagon.
If you're interested in RSS but you don't know where to start learning about it, Lee and Sachi LeFever of The Common Craft Show have created RSS in Plain English, a breezy video that explains it in under four minutes.Click To Play
R|mail.The following RSS Advisory Board proposal has been made by Randy Charles Morin and seconded by Rogers Cadenhead.Under the advisory board charter, the board has seven days to discuss the proposal followed by seven days to vote on it. Interested...
R|mail.In part I of the my articles on multiple-enclosures, I describes why I think the spec is clear that RSS <item>s may only contain on <enclosure>. The best response I got was a questioning of how do I know the intent of the author. My response was that the original author told us his intent was one or zero enclosure per item.
In this part, I want to describe various scenarios showing how multiple-enclosures should be supported in RSS. There are numerous reason why a publisher would want to include more than one enclosure in an RSS item. Let me describe some. If I missed one, then drop me an email and I can address your specific scenario too.
Sometimes an RSS publisher would like to attach a media file in several different languages. This is almost always a fundamental misuse of the enclosure. Even if you could have multiple-enclosures, then why would any user want to download your audio or video in several languages? Surely each user is interested in one specific language. In this case, it's almost always best to have one RSS feed for each language. Otherwise, each user may be downloading several times more media bytes than he really requires.
Sometimes an RSS publisher would like to attach a media file in several different formats. For example, he may want to attach a WAV file and an MP3 of the same audio compilation. This isn`t really different from the scenario above. A separate feed should be provided for each format. The user can then decide why format is best for him.
Sometimes an RSS publisher would like attach different media types with similar content. This might be an MP3 and an MPG. In this case, not only is the format different, but the basic media type is also different; audio vs. video. This is an interesting scenario. The best approach is likely also to ave two different RSS feeds, one for the audio and one for the video. A user could subscribe to his preferred media or both.
The last common scenario is where the user wants to attach two or more media each with unique content. Let`s make up an example to suit this scenario. Imagine an RSS feed for movie reviews, with a video attachment, the movie trailer and an audio file, the review of the critic. There are several ways of handling this type of multi-enclosure scenario, but offering multiple RSS feeds is not really an option. In the previously scenarios, the same content was being offered in different languages/formats. In this scenario, it's not a language/format difference but actual content. In this case, there's no reason to have multiple RSS feeds.
The question becomes how to allow for multiple-enclosures when multiple-enclosure per item is not allowed.
The first solution to this problem is to have one <item> element per enclosure.
<rss version="2.0">
<channel>
<title>sample</title>
<description>sample</title>
<link>http://sample</link>
<item>
<title>sample</title>
<description>preview for sample</description>
<enclosure url="http://sample/sample.mpg" length="23456" type="video/mpeg"/>
</item>
<item>
<title>sample</title>
<description>review for sample</description>
<enclosure url="http://sample/sample.mp3" length="12345" type="audio/mpeg"/>
</item>
</channel>
</rss>
In this case, there's a lack of binding between the two enclosures. Other than maybe a similar title, it's not programmatically possible to tell than the two RSS <item>s are related. This can make the job of the podcatcher a bit difficult and the experience of the user confusing.
A second solution is to use the Yahoo! media RSS extension to describe the second (and any further) enclosures.
<rss version="2.0" xmlns:media="http://search.yahoo.com/mrss/">
<channel>
<title>sample</title>
<description>sample</title>
<link>http://sample</link>
<item>
<title>sample</title>
<description>preview for sample</description>
<enclosure url="http://sample/sample.mpg" length="23456" type="video/mpeg"/>
<media:content url="http://www.foo.com/movie.mp3"
fileSize="12345" type="audio/mpeg" medium="audio" />
</item>
</channel>
</rss>
In this case, we provide two enclosures by re-using Yahoo!`s media RSS extension. The binding between the enclosures is obvious. The only problem with this technique is that Yahoo! media RSS is not as well supported as the base enclosure element. Mind you, I think the difference in support level is very minimal.
There are likely some exceptions to the rules above. In fact, there are likely many exceptions. There are so many use cases for RSS enclosures that even a 1% exception rate would mean hundreds, maybe thousands of exceptions. If you can`t figure out the exceptions on your own, then ping me with an email [randy@kbcafe.com] and I`ll try to help.
It's also possible that you disagree with my multiple-enclosure thoughts. In that case, I'd love to hear why. Please reply in the comments.
R|mail.Today, I decided to give Netvibes another shot. Mostly because I have another reason to evaluate Netvibes (work). The Netvibes user interface is exceptional. There doesn't appear to be a better AJAXian experience. The defaults were very accurate, I'm not sure why they thought I need Paris, France weather, but Canadian and in particular, hockey news, was right up my alley.
At some point, I realized that I wasn't even logged-in. I've always been extremely impressed with unregistered user customization. I then created an account. Wow! Quite an experience. These guys have user experience down to an art.
Before I signed-up, I imported my exported OPML RSS reading list from Rmail. Netvibes puts my list of subs in a folder in the left sidebar. Huh? Now what? I can't figure out what to do from here. It seems that I'd have to manually add each subscription to my tab. I then decided to delete my subscriptions and start all over. That option isn't available either. So, I imported the same OPML a second time, but this time I selected to add the feeds to a new tab. Waiting... waiting... waiting... bye! Support for RSS power users seems to be non-existent.
I've tried all sorts of social networks; Frienster, LinkedIn, MySpace, Tribe and much more. They all seemed very forced. I had a few real friends in the network, it was mostly blogosphere geek friends. Not that blogosphere friends aren't real, but I had never met most of them in real life. It wasn't a real representation of my life. I'm sure that was different with high-school students and valley geeks, whom had plenty of friends in the network. Facebook, on the other hand, is full of my real friends. I've hooked up with a dozen friends that I haven't met in 15 years. Instead of people posting spam on my profile (MySpace), my wall (Facebook) is full of comments from long lost friends. I've even talked to my wife, the ultimate non-geek, about Facebook and she knew what I was talking about. My wife has surfed the net only a few hours in her entire life. She doesn't have a profile on Facebook, but she knew the geekery I was talking about. It's exciting to get new comments on your Facebook wall. Nobody is trying to sell me viagara or call girl services.
Somehow, the debate about how to encode RSS text elements has re-surfaced. I personally thought this was resolved, but clearly the debate rages on. The problem with encoding derives from the fact that certain characters, like ampersand (&) have special meaning in XML, so care must be made to encode them. As a starting point, let's consider the following XML fragment.
<title>How to encode & in XML</title>
This XML fragment is not well-formed in itself. That's because the special ampersand character must be encoded.
The most simplest way to encode the ampersand is to replace it with the string "&". The valid XML fragment would look like the following.
<title>How to encode & in XML</title>
When this is decoded, the XML text becomes "How to encode & in XML". This is called entity encoding. There are at least three other ways of encoding the same information.
Immediately, we have four different ways of encoding an ampersand. All four are valid for encoding an ampersand in an RSS <title> element. All four are called single encoding, because we`ve encoded the data exactly once.
There`s also a reason to encode the data twice. This happens when we want to encode HTML within an XML element. This is necessary because the RSS specifically allows this for the <description> element.
the description contains the text (entity-encoded HTML is allowed; see examples)
Now, it must be pointed out that the spec uses entity-encoded HTML but refers to examples that are both CDATA encoded and entity encoded. That's OK, I'm capable of making the leap of faith that he meant double encode the <description>. Let's make clear that this means the <description> child element of <item> is double encoded. The <description> child element of <channel> remain single encoded. All other elements are single-encoded, including the <title>.
The best article written on the subject was by James Holderness, titled Encoding RSS Titles. Let's use this as a starting point. James did a great job of enumerating what works and doesn't work and he summarizes as follows.
Clearly if you want to support Firefox or Internet Explorer you├ó┬Ć┬Öve got no choice but to use the single encoding option. For certain strings, though, that would mean losing support for at least twenty other aggregators. No matter what you do, you can├ó┬Ć┬Öt win.
Perhaps the only solution, barring a miraculous change of policy on the part of certain browser authors, is to just use both.
What the first sentence means to me is that publishers should single-encode their <title>s. The second sentence was a more complex solution where the publisher could use User-Agent sniffing to server the <title> as either single or double-encoded depending on what the user-agent supported.
Kent Newsome coined a new term (at least for me) called the unblogosphere. This is the blogosphere equivalent of the unconference. That is, that knowledge is distributed throughout the blogosphere. The problem, of course, is that the same group of a-listers continue to get all the attention, similar to the way a conference session is controlled by the conference speakers. In an unconference, everybody in the audience is given a voice. The truth is, the blogosphere is already an unblogosphere. Everybody has a voice. The problem is that you can`t hear Kent`s voice because everybody else is talking at the same time. But some voices get thru, like Dave Winer`s. The reason his voice gets thru is because everybody keeps linking to the same a-listers. In fact, Kent linked to Dave in his post about the unblogosphere. The a-listers aren`t stupid, they crosslink with each other daily. That`s how they remain a-listers. And every once in awhile a new blogger breaks into the a-list group and they begin linking him up as well. The a-listers aren`t stupid. The b-list and c-listers are the problem. Most b-list and c-list bloggers link to an a-lister with every post. The truth is, the a-listers will rarely ever read your post, because hundreds of bloggers are linking to them everyday. Note there fault, they are busy. If people want an unblogosphere, then it`s gonna have to start with the b-list c-list bloggers. They have to start linking to each other and stop their persistent linking to the a-list, hoping for that one juice boosting link back that never comes.
http://www.newsome.org/2007/05/neither-is-blogosphere.shtml
I linked up some b-list and c-list bloggers in this rant. Not to point to them as a problem, but to give them the Google juice well deserved. I`m also part of the problem and intend on changing that.
A new draft of the RSS best-practices profile has been published. It includes help on how to properly format e-mail addresses in RSS elements. Feedback is encouraged on RSS-Public.
R|mail.
R|mail.Last week, Cognitive Daily moved to full feeds. This week, they moved back to partial feeds. They presented some data to validate their decision. It's worth a read if you follow the full vs partial feed debate.
Some of my own thoughts follow...
http://scienceblogs.com/cognitivedaily/2007/05/our_rss_experiment.php
http://scienceblogs.com/cognitivedaily/2007/05/the_end_of_the_rss_experiment.php
R|mail.One of the biggest debates in RSS-land is multi-enclosures. How do you do them? Can an item have more than one enclosure? How do I include enclosures in multiple languages? multiple formats? Trying to gain consensus on this issue is like trying solve the Iraqi civil war. It may take a generation. So, your best bet is to get all the cards on the table and make the best decisions with what we have.
The best place to start is the spec text. The spec doesn't really say to much. Under <item> it says "All elements of an item are optional, however at least one of title or description must be present" and lists enclosure as one of the optional child element with the description "Describes a media object that is attached to the item." Then under <enclosure> the complete text follows in the block quote.
<enclosure> is an optional sub-element of <item>.
It has three required attributes. url says where the enclosure is located, length says how big it is in bytes, and type says what its type is, a standard MIME type.
The url must be an http url.
<enclosure url="http://www.scripting.com/mp3s/weatherReportSuite.mp3" length="12216320" type="audio/mpeg" />
A use-case narrative for this element is here.
The use-case narrative, Payloads for RSS, describes how the enclosure was intended for use. In short, the RSS aggregator would suck down the media files in an RSS feed overnight. There's a short description of the new element, which is included in the next block quote.
So that's the philosophy, now let's put some meat on the bones.
RSS already does most of what we want. With the addition of the <enclosure> sub-element of <item> any RSS element can describe a video or audio file (actually any type of file).
<enclosure> has three attributes: url says where the file is located, length says how big it is, and type says what its type is. This way a workstation or aggregator can know in advance, without having to do any communication, what it's going to get, and apply scheduling and filtering rules.
With all this on the table, what does this say about the cardinality of the <enclosure> element in <item>? It says that it's OPTIONAL. If a lawyer read this, then he'd likely say that the element can be present or not. If an Enlish professor read this, then he'd likely say that the element can be present or not. Both the lawyer and professor would likely argue that it says nothing about whether two enclosure elements may be contained within the item parent element.
Now, if someone family with XML schemas read this, then he'd likely say that the enclosure element can have zero or one instance in the parent item element. Why would he exclude multiple instances? Because in XML schemas, the word OPTIONAL has come to mean zero or one, not zero or one or more. Let's take a look at several examples of this.
We'll pretend Google is the official reference to the galaxy (which it is) and query the web for xml dtd optional element. The first article is by Ronald Bourret and it's called Declaring Elements and Attributes in an XML DTD. In one section, he talks about the cardinality of elements and specifically says "Optional (?), one-or-more (+), and zero-or-more (*) operators can be applied to groups, subgroups, and subelements". Note the question mark operator in DTD means zero-or-one and he makes the same assumption that optional implies zero-or-one. Next we get L. Dodds The 10 Minute Guide to Reading an XML DTD. He also uses the word optional to denote the zero-or-one operator in DTDs, although he does note at most one to remove any confusion. The third article is a forum post titled PCDATA followed by an optional element. The author here again uses the word optional to mean zero-or-one.
Now, RSS wasn't written by professors or lawyers, it was written by a computer scientist and it's an implementation of XML. OPTIONAL means zero-or-one in this context. I'm sure some will continue to disagree, but then I have to bring up a further point. If you read OPTIONAL as zero-or-more in the RSS spec, then how many optional <title>s, <link>s and <description>s can an RSS item have? Too many.
The only way to read the spec is that there is at most one instance of enclosure in item. In part II, I'll describe how to implement multiple enclosures now that sane people agree you can only have at most one enclosure in any RSS item.
R|mail.
R|mail.Om Malik is reporting rumors that FeedBurner is being traded to team Google for $100M. As predicted. They are clearly worth more than $53M. Trust me, I know.
R|mail.The RSS team at Microsoft has documented their right-to-left text support in IE7. Basically, they use the <language> element in the RSS, the default language of the Web browser and the manual browser settings to determine the reading order.
http://blogs.msdn.com/rssteam/archive/2007/05/17/reading-feeds-in-right-to-left-order.aspx
James Snell also points us to his Atom draft that addresses bi-direction text support.
http://www.ietf.org/internet-drafts/draft-snell-atompub-bidi-04.txt
My friends at Yahoo! just told me that MyYahoo! Beta just got a little better today with some new features. New is a WYSIWYG inline personalization component, so you can edit your MyYahoo! page without ever leaving it.
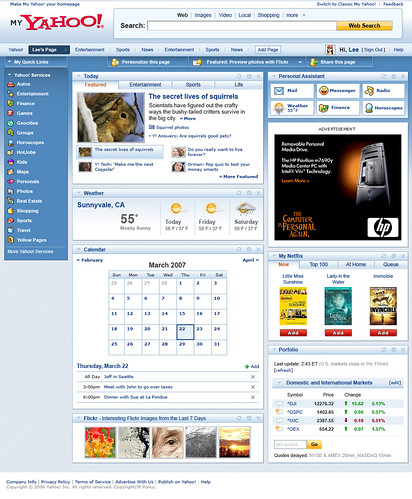
I've never really liked MySpace. I use it because I want to stay in touch with what's hot. I've ignored Facebook, because I saw it as just another MySpace. In the last few days, I started poking around Facebook. I've hooked up with two childhood friends. We're sharing photos. This actually works. Now, I might get bored of it later, but right now, I'm actually excited when I get a Facebook email.
One problem, the Java-based photo uploader doesn't work. It takes several minutes to upload 76k photos and it always fails.
Update: Even the HTML form uploader is slow, but at least it works sometimes.
Wikis are now polluting the Google SERPs. I'm not just saying Wikipedia, I'm talking about all Wikis. For instance, when I search for HR-XML resume, I get the E-Learning Framework wiki which contains a near zero content webpage about HR-XML resume. Wikis use internal link structures to boost their Google juice. This is really beginning to pollute the SERPs. Google has to do to Wikis what they did to blogs. Pull out wikis into a separate search engine. In fact, some young entrepreneur should start a wiki search engine and sell it to Google.
R|mail.
R|mail.Chip tagged me with a new meme called What's Your Web 2.0? Basically, you enumerate all the websites that you use; daily, weekly and monthly. I'm a heavy Web 2.0 user, so I'm gonna go with hourly, daily and weekly instead.
Hourly use
Daily use
Weekly use
I hope I didn't forget anything. I'm going to tag Joseph A Nagy Jr, Oleg Dulin, Scott Kingery, David Rothman, Tom Simpson, Aimee Evans, Jason Schramm, David Walker, Alec Saunders, Tim Dungan and Steve Michel. Tell us what your Web 2.0 is.
A new draft of the RSS best-practices profile has been published. It includes a new section on using an Atom element to identify an RSS feed's address. Feedback is encouraged on RSS-Public.
R|mail.Rogers Cadenhead has published a new version (1.15) of the RSS profile. Please review the profile leave comments on the rss-public message board. I'd like to see this presented and approved by the board by May or June. Let's get this done.
Rogers Cadenhead explains the difference between the legacy RSS 2.0 specification published by Harvard and the latest RSS 2.0 specification published by the RSS advisory board.
https://workbench.cadenhead.org//news/3213/linking-rss-20-specification
As chairman of the RSS Advisory Board, I've been called into two discussions recently about where people should link when referring to RSS 2.0. There are two leading contenders: the RSS 2.0 specification published by the board and an older...
R|mail.
R|mail.It's not exactly clear in the blog entry, but Syndication Gumption has quoted Neilsen/NetRatings reporting that 20-25% of the Yahoo! news traffic is coming via RSS URLs.
We have determined a URL coded to the Yahoo! News definition (rss.news.yahoo.com) should be removed from the reporting data beginning with April 2007. The URL contributed traffic to Yahoo! News throughout the past 13 months (March 2006 - 2007) - providing a small amount of incremental Unique Audience for the Channel (2-3%) but, in recent months, contributing as much as 20-25% of the page views and time spent.
A more complete quote and context would shed more light if a reader would like to provide that.
R|mail.
R|mail.Mark Woodman of TechBrew is looking for an RSS distribution rights RSS extension. Mark mentions that the core RSS <copyright> element is too free-form. I agree. He also suggests that a CreativeCommons solution is too course-grained. I'd just like to add a pointer to that debate. There exists a CreativeCommons RSS extension. I tend to agree with Mark. There's a need. A need that maybe the RSS Advisory Board can fill.
http://techbrew.net/articles/200705/splashcast-and-the-podcast-distribution-problem/
Just in time for Nick Bradbury's 40th birthday, The RSS Blog readers have named him the top RSS thinker. Nick, the creator of FeedDemon, actually tied for first with his boss, Greg Reinacker, CEO of NewsGator. Dave, Rogers, the user and Sam rounded out the top 6.
I was surprised that Dick Costolo, founder of FeedBurner and Adam Curry, father of podcasting, didn't get more votes.
R|mail.Facebook has partnered with Oodles to provide classifieds for students. This looks like a great deal on the front, but you have to wonder what is up. Facebook opened up beyond their school-age end-user roots. This is clearly a move back to that verticle. Personally, I think they'd do much better sticking to that verticle. But why Oodle? This is a company that was booted by Craigslist for violating its terms of use. Is this the type of company you want to partner with? This could have been an opportunity for Facebook to deal with campus exchange startup like NexusTrade.
Update: Facebook must be listening. They've started their own NexusTrade.
R|mail.I just coded against Facebook API to import profiles into ResumeBay. Facebook's API is so complex that it is beyound the capability of the average developer.
http://www.resumebay.net/blog/?guid=20070510163857
http://www.kbcafe.com/csharp/?guid=20070510145637
R|mail.
R|mail.
R|mail.
R|mail.
R|mail.Dave Winer: I think I understand why the Digg users got so upset. They weren't consulted. They weren't included in the decision. Their opinion, the core value that Digg "owns" if they own anything, wasn't sought. That was the source of the anger.
http://www.scripting.com/stories/2007/05/03/whyTheUsersOfDiggGotPissed.html
I wrote more on Splashcast's feed hi-jacking and content theft over on the Destroy All Malware blog.
http://www.kbcafe.com/spam/?guid=20070503104841
Update: It appears that SplashCast has stopped hi-jacking RSS feeds.
Yesterday, Douglas Karr left a very challenging comment on Chip' Quips. Basically, Douglas wants to use RSS as an envelop for his resume. Others could subscribe to his resume and get an update whenever his resume changes.
http://www.chipsquips.com/?p=837#comment-43978
Douglas has written before on this subject. He would like to do a tag query on Technorati and find matching resumes.
http://www.douglaskarr.com/2006/12/20/peace-2/
Standards for embedding resumes in RSS already exist. Microformats is the most commonly used format, but you can also simply embed an HR-XML Resume object in your RSS <item>. So, I decided to make this functionality available on ResumeBay. Hack. Hack! And done.
In what could only be described as an awakening of the Digg community, the Digg team have bowed to the power of their own community. This is a great social web interest story and one lesson that should be learned by anybody interested in building an online community. It's all about the following number.
09 F9 11 02 9D 74 E3 5B D8 41 56 C5 63 56 88 C0
What is important about this number? "It's the HD-DVD processing key you can use to decrypt and play most HD-DVD movies." And of course, it got Dugg. And the Digg team received a cease and desist declaration. They chose to take it down and the community fought back by posting the number in hundred of Digg stories. In the end, the Digg team gave in. From Kevin Rose "If we lose, then what the hell, at least we died trying."
The father of RSS and blogging is 52 years old today. Happy birthday Dave!
Todd Cochrane has gone into more detail as to his RSS hijacking concerns with Splashcast. In particular he notes that Splashcast was offering Todd's podcasts as a channel with an RSS feed hosted by Splashcast. In fact, they are also offering an array of subscription chicklets to encourage the user to subscribe to the Splashcast feed, instead of the source feed.
And of course, Marshall Kirpatrick responded to Todd's post. And of course Todd was confused by his response. This seems to be a common thread of conversation across the blogosphere. Someone doesn't like what Splashcast is doing. Marshall responds with irrelevant promotional statements about Splashcast and says don't worry, we'll take care of the problems. I have to agree with Todd and the rest. I'm confused.
Now, I'm the first person to encourage new business ideas around RSS. Splashcast looks like a cool idea. How long would it take Splashcast to stop hi-jacking? Isn't that 2 lines of code? I think the blogosphere has given the 24 hours of required notice. Splashcast must stop hi-jacking immediately.
Marshall has been around the blogosphere for quite some time and he's quite familiar with RSS hi-jacking issues. In fact, it was Marshall that said "Major, major badness issue" when he found that Feedpass could be used to hi-jack an RSS feed. So, I'm confused. What's up Marshall?
Update: Still hi-jacking 24 hours later?
This last week, I starting using the Google Apps domain email solution for two of my domains. I have to say, I'm quite impressed. Because I only need one email address for these domains, it's free. With all the problems I have to for fee email hosting, I'm definately considering a permanent move. On the other hand, I'm no impressed with Gmail's ability to put spam in my inbox and emails from friends in the spam box. I might give Yahoo! mail another try.
Other than YouTube, the podcasting and videocasting industries have been very dry these last few months. Yesterday, Marshall Kirkpatrick announced a podcasting mashup called MyPodcastNetwork from his startup SplashCast. MPN is a widget that allows you to put your favorite RSS enclosures on your blog or website. I found the MPN viewer loads very slowly and the video is very jerky.
http://splashcastmedia.com/podcasterfaq
Around the blogosphere...
Personally, I'm still waiting for a complete podcast management solution that also does broadcasts and viewer/listener chat.
Microsoft has announced a data web services framework called Astoria. I've not been able to access the website and play with it, but according to the blogosphere reports, its a framework for data web services. Alex Barnett has the best explanation with concrete examples.
http://astoria.mslivelabs.com/
Around the blogosphere...
IMHO, this looks a lot like Microsoft's attempt at standardizing data access over SQL (OLEDB). Grand, but doomed. I'm not gonna right-it-off until I give it a test drive, but I've got that "Yet Another Framework" feeling.
The RSS Blog is published by Workbench


